Embedding models
Embedding models create a vector representation of a piece of text. You can think of a vector as an array of numbers that captures the semantic meaning of the text. By representing the text in this way, you can perform mathematical operations that allow you to do things like search for other pieces of text that are most similar in meaning. These natural language search capabilities underpin many types of context retrieval, where we provide an LLM with the relevant data it needs to effectively respond to a query.
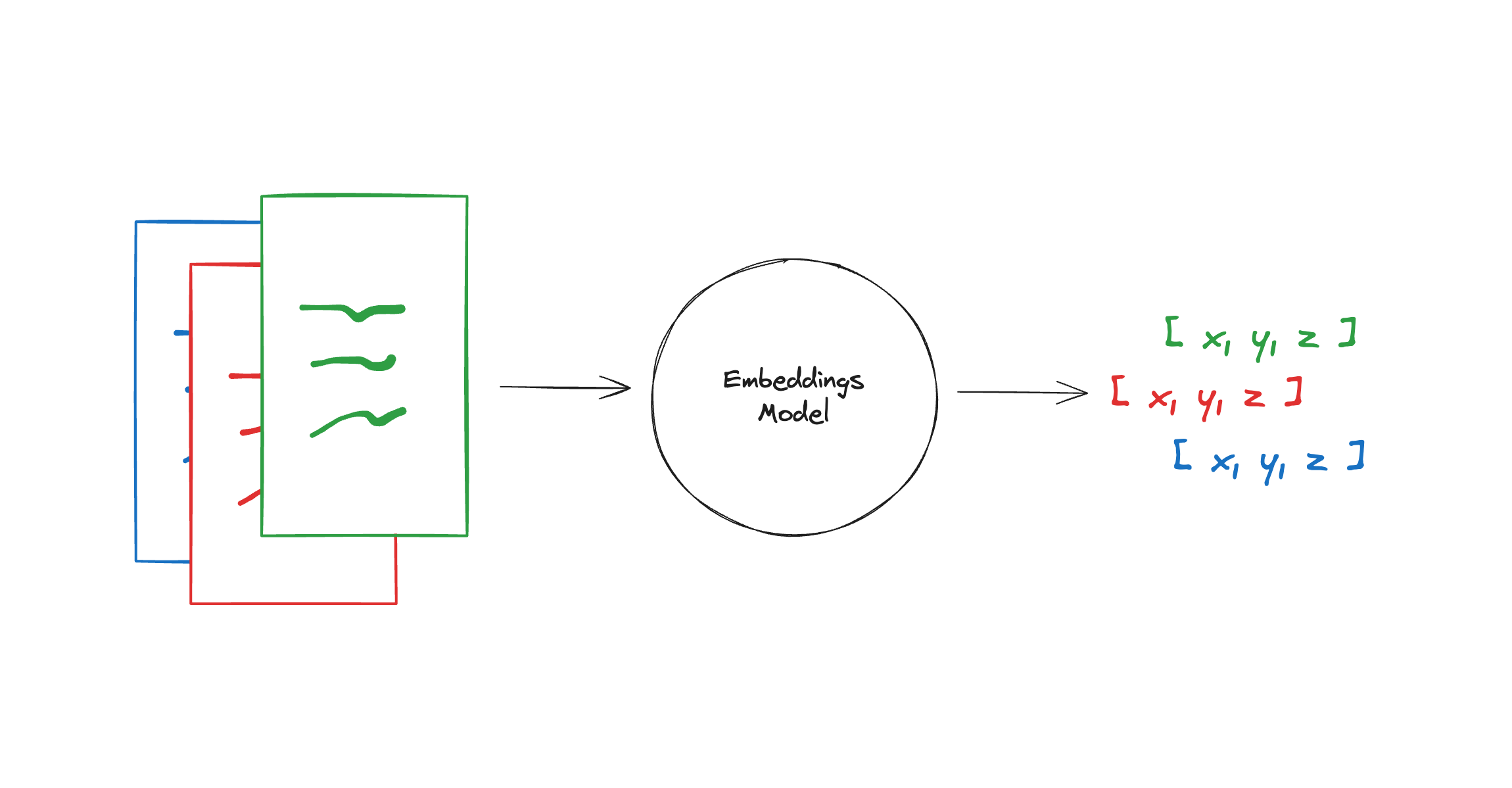
The Embeddings class is a class designed for interfacing with text embedding models. There are many different embedding model providers (OpenAI, Cohere, Hugging Face, etc) and local models, and this class is designed to provide a standard interface for all of them.
The base Embeddings class in LangChain provides two methods: one for embedding documents and one for embedding a query. The former takes as input multiple texts, while the latter takes a single text. The reason for having these as two separate methods is that some embedding providers have different embedding methods for documents (to be searched over) vs queries (the search query itself).
For specifics on how to use embedding models, see the relevant how-to guides here.